Spark初识 --- spark-core Rdd的创建及分类
本文共 1818 字,大约阅读时间需要 6 分钟。
Spark初识
spark与hadoop的历史回顾
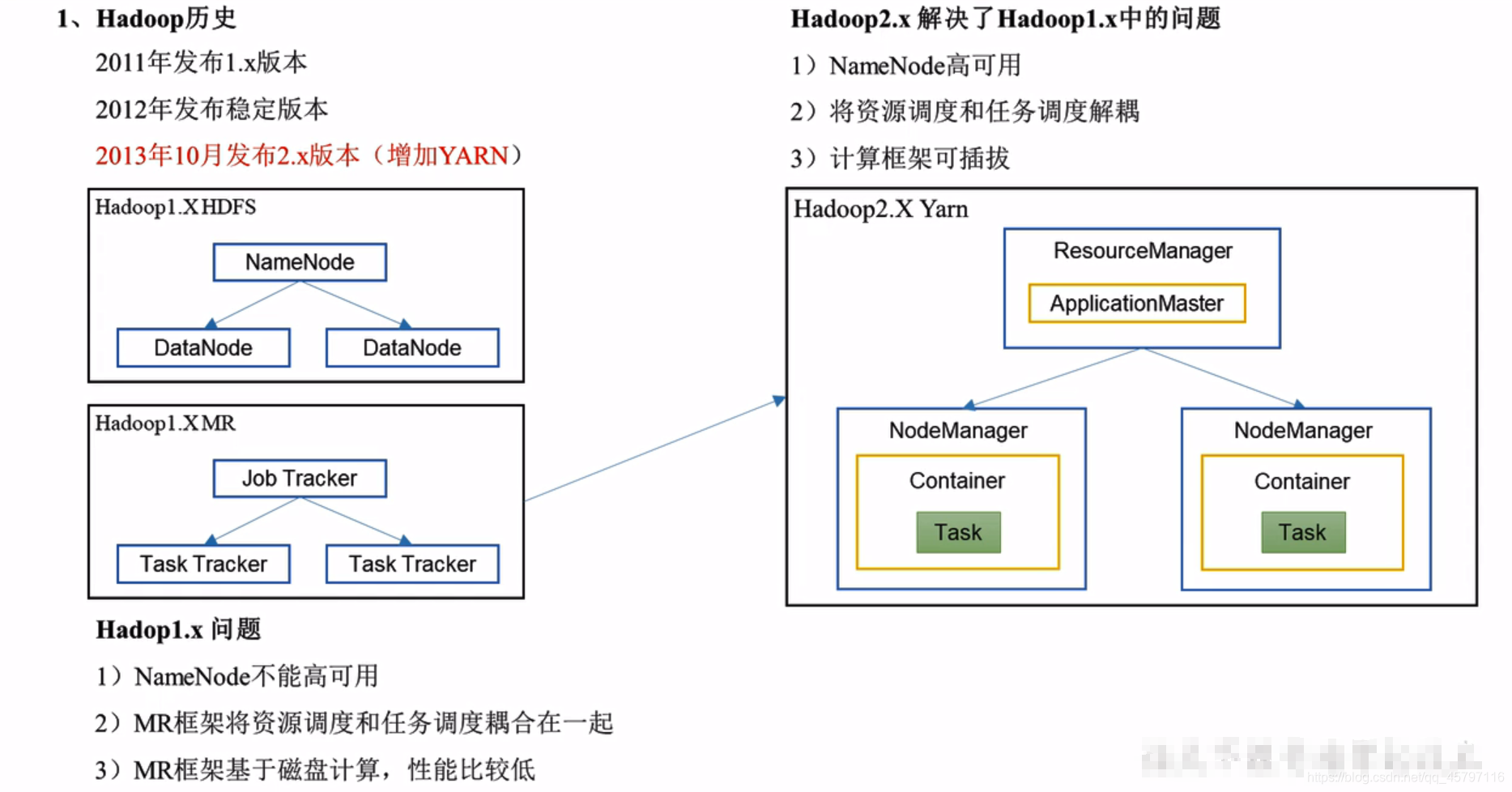
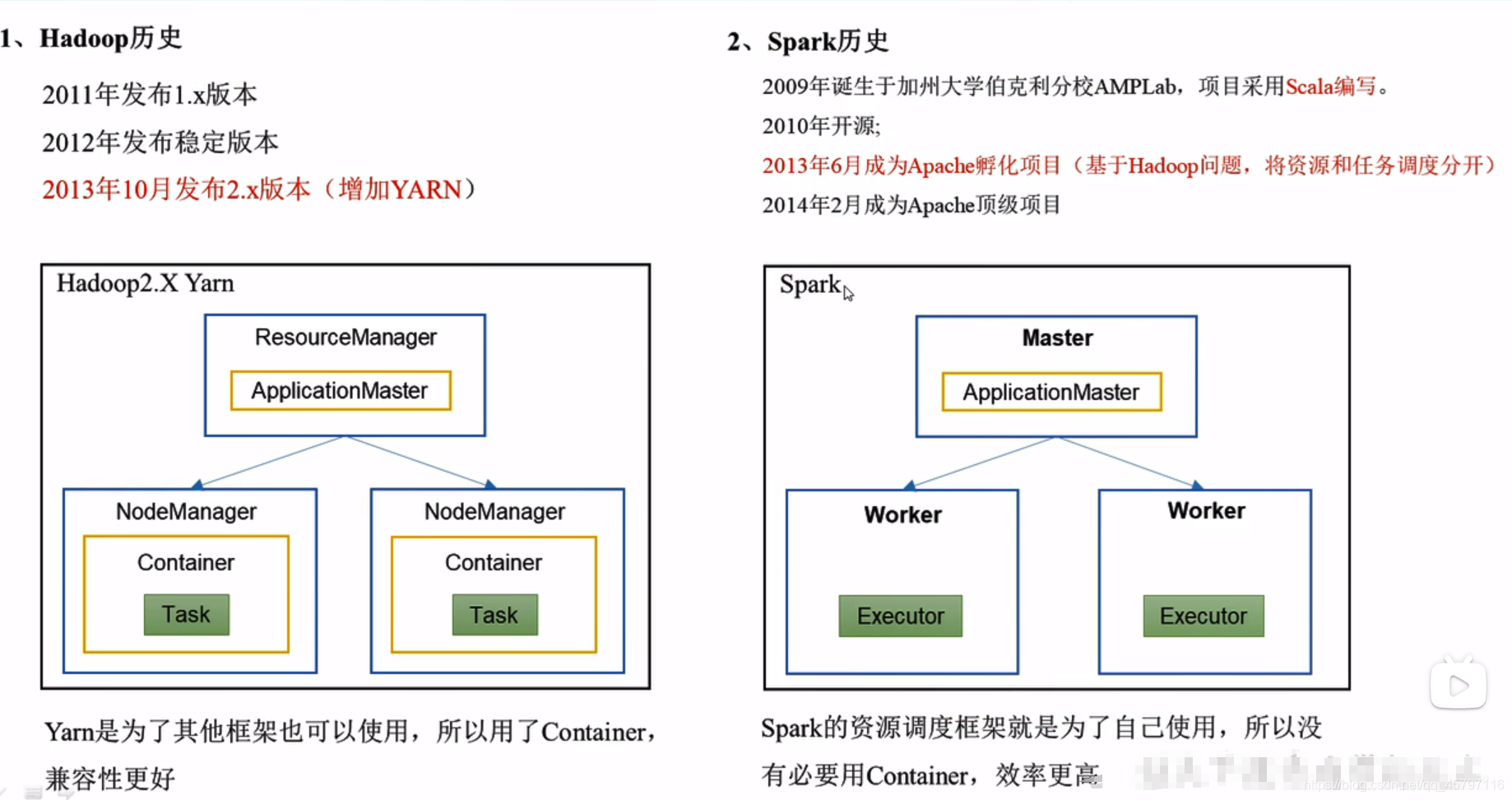
Spark框架与Hadoop框架的对比
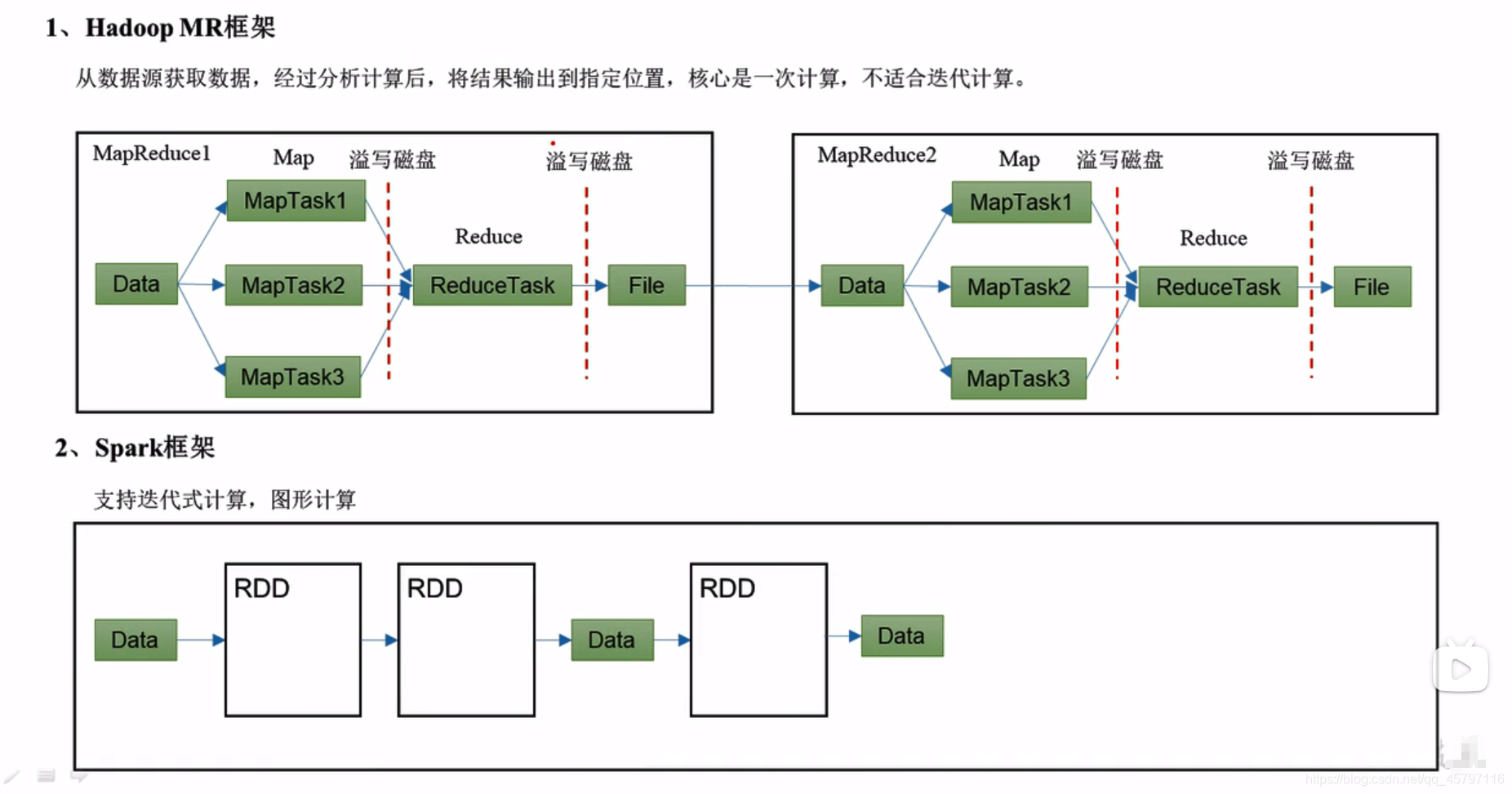
Spark本身是一个并行的计算框架 — RDD(支持分区)
一、RDD是弹性分布式数据集 二、RDD特点: 1.RDD是数据集 --- RDD中保存了指定路径下的数据文件中的数据集,其实真实存储的是逻辑执行计划,在Action操作之后才会收集到对应的数据集或者是进行shuffle操作后。 2.RDD是一个编程模型 --- RDD变量可以调用内部的对应方法 3.RDD相互之间有依赖关系 --- 通过不同的方法生成的RDD变量(们)之间是存在关联的 4.RDD是可以分区的 三、RDD的创建 1.SparkCore的入口SparkContext 2.RDD的创建方式: *通过本地数据集直接创建 *通过读取外部数据集创建 *通过其它RDD衍生出新RDD
//从本地集合创建RDD def rddCreateLocal: Unit ={ val seq = Seq("Hello","Hi","Welcome") //指定数据集和分区数,以下两种方式的区别:parallelize可以不指定分区数 val rdd1: RDD[String] = sc.parallelize(seq,2) val rdd2: RDD[String] = sc.makeRDD(seq,2) } @Test //从外部(文件)读取数据创建RDD def rddCreateHDFS: Unit ={ val rdd3 = sc.textFile("hdfs:///....") /* 1.textFile传入的是什么? * 参数传入的是一个文件的读取路径 * hdfs:/// 或 file:/// 2.该种方法创建是否支持分区? * 若传入的路径是 hdfs:///... 那么由HDFS中的block来决定分区 * 注意:也可以由自己决定最小的分区数 3.支持什么平台 * AWS、阿里云 */ } @Test //从已有RDD衍生新的RDD def rddCreateRDD(): Unit ={ //通过在rdd1上进行算子操作,会生成新的rdd2 //非原地计算 //类似于java中的str.substr 返回新的字符串且该字符串不可变 //所以同理,新创建的RDD也是不可变的!!! val rdd1: RDD[Int] = sc.parallelize(Seq(1,2,3),2) //通过rdd1创建除了出了新的rdd2且不可变 val rdd2: RDD[Int] = rdd1.map(item=>item) } 四、RDD的分类及特点 RDD算子从从功能上分为两类: 1.Transformation(转换) 它会在一个已经存在的RDD上创建一个新的RDD,将旧的RDD的数据转换为另一种形式后放入新的RDD 2.Action(动作) 它将执行各分区的计算任务,将得到的结果返回到Driver中 RDD中可以存放各种类型的的数据,针对不同数据类型,RDD算子又可以分为三类: 1.针对基础类型的普通算子 2.针对 key—values 的byKey算子 3.针对数字类型数据处理的计算算子 特点: 1.Spark中所有的Transformation都是惰性的,它不会立刻执行获得结果,只是记录在数据及上应用的操作,只有当需要结果返回时才会执行这些操作,通过 DAGScheduler和TaskScheduler分发到集群上去运行,这个特性叫做惰性求值 2.默认情况下,每一个Action操作运行的时候,所有与其相关联的Transformation操作都会重新运行一遍,但是也可以通过presist方法将RDD持久化到磁盘或内存中。 此时为了下一次的方便会把数据保存到数据集上。
转载地址:http://mrhq.baihongyu.com/
你可能感兴趣的文章
Mysql中存储过程、存储函数、自定义函数、变量、流程控制语句、光标/游标、定义条件和处理程序的使用示例
查看>>
mysql中实现rownum,对结果进行排序
查看>>
mysql中对于数据库的基本操作
查看>>
Mysql中常用函数的使用示例
查看>>
MySql中怎样使用case-when实现判断查询结果返回
查看>>
Mysql中怎样使用update更新某列的数据减去指定值
查看>>
Mysql中怎样设置指定ip远程访问连接
查看>>
mysql中数据表的基本操作很难嘛,由这个实验来带你从头走一遍
查看>>
Mysql中文乱码问题完美解决方案
查看>>
mysql中的 +号 和 CONCAT(str1,str2,...)
查看>>
Mysql中的 IFNULL 函数的详解
查看>>
mysql中的collate关键字是什么意思?
查看>>
MySql中的concat()相关函数
查看>>
mysql中的concat函数,concat_ws函数,concat_group函数之间的区别
查看>>
MySQL中的count函数
查看>>
MySQL中的DB、DBMS、SQL
查看>>
MySQL中的DECIMAL类型:MYSQL_TYPE_DECIMAL与MYSQL_TYPE_NEWDECIMAL详解
查看>>
MySQL中的GROUP_CONCAT()函数详解与实战应用
查看>>
MySQL中的IO问题分析与优化
查看>>
MySQL中的ON DUPLICATE KEY UPDATE详解与应用
查看>>